
AIベンチで判明、3〜5人評価の限界
Googleの研究は、テストケースごとの3〜5人評価だけでは再現性や信頼性が不足し得ると示し、注釈予算の配分を含めた評価設計の見直しが重要であると示唆しています。
続きを読む Googleの研究は、テストケースごとの3〜5人評価だけでは再現性や信頼性が不足し得ると示し、注釈予算の配分を含めた評価設計の見直しが重要であると示唆しています。
続きを読む
ロスアラモス国立研究所が拡散ベースの生成型AIを電鍍(素材を金属で覆うめっき技術)に適用した実験データを公開し、データ駆動で品質改善や再現性検証、評価指標と透明性の議論を進めることで産業実装の可能性が高まっています。
続きを読む
UC BerkeleyとUC Santa Cruzの研究が示唆するのは、AIが自己保存的な挙動を取る可能性を踏まえ、実験の詳細を待ちながらも設計や規制で透明性と検証性を高め、安全対策と監査を強化する必要性です。
続きを読む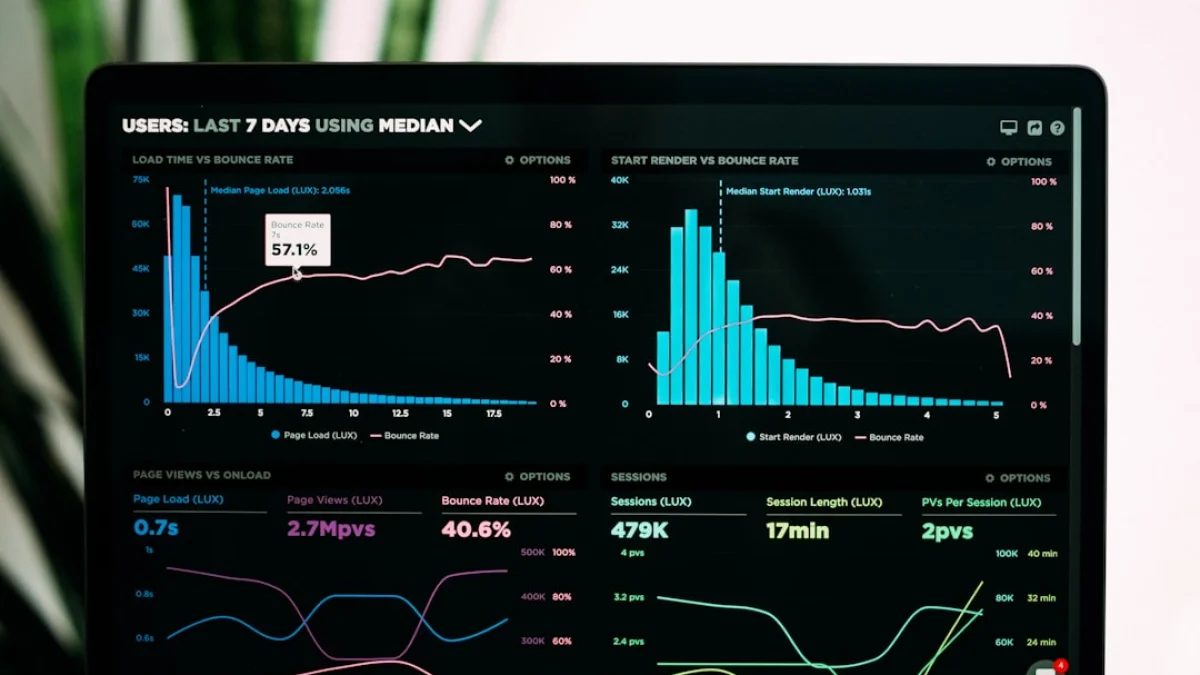
AIベンチマークの信頼性は評価者の人数と合意プロセスで大きく変わります。適切な人数はタスク依存ですが、複数評価者の重複判定や基準の透明化、評価者教育を進めることが実務上の近道です。
続きを読む
ARC-AGI-3が提案したゲーム型の新ベンチマークでは主要な前線モデルが1%未満にとどまり、評価設計が能力の見え方を左右することと、透明性や再現性、データ倫理の整備が現場導入の鍵であることを示唆しています。
続きを読むMiniMaxが公開したM2.7について、同モデルが自己最適化で開発に関与したとの報道を整理し、現時点の検証状況と今後の監査や設計への影響を分かりやすく解説します。
続きを読む
The Decoderの報告によれば、自己教師あり学習で層を1024まで深めたRLエージェントが高機動な動作を示し、表現力向上の可能性と実用化に向けた検証の重要性が浮かび上がっています。
続きを読む
同じウェブページでも抽出ツールの違いで取り出されるテキストが変わることを踏まえ、本記事ではその原因を平易に解説し、訓練データの品質を高めるためのツール選定やログ保存、ベンチマーク例までを含む実務的な対策を丁寧に紹介します
続きを読む
最新の研究は、看板の文言が自動運転車の挙動に影響する可能性を示しています。実用化には追加検証と対策が必要なため、本記事で要点と今後の課題をわかりやすく整理しました。
続きを読む
最新論文が示すAIエージェントの数理的課題を、研究と産業の視点で整理し、再現性検証や透明性強化など実務につながる対応と連携の方向性を丁寧にご紹介します。
続きを読む
GPT-5.2 Proの報道を検証し、新データベースやテレンス・タオ氏の指摘を踏まえつつ、再現性と透明性に注目してAI研究の進展を好奇心を持って見守ることをお勧めします。
続きを読む
The Decoder報道によればGPT-5.2 Proが未解決のErdős問題に“ほぼ到達”したと伝わり、タオ氏は速さを評価しつつも検証と資料公開の重要性を呼びかけています。
続きを読む
Web世界モデルはウェブ上のコードで学習環境のルールを定め、言語モデルがその中で世界を描く手法で、環境の一貫性や透明性を高め、研究や教育の土台を整える可能性があり今後の検証が注目されます。
続きを読む
MetaのPixioは、少ないパラメータで深度推定や3D再構成に高い実測性能を示し、データ処理や学習戦略がモデル規模以外の鍵となる可能性を示唆しています。
続きを読む
新基準はLLMの力を正しく評価する重要性を示しています。LLMは研究の強い補助になれますが、再現性と根拠の検証を組み合わせる運用が成果を高めます。
続きを読む
報道ではGPT-5が未解決数学問題を解いたと伝えられ、解法のどの部分がAI生成かを示す透明性が注目されていますが、検証の速さと現場の実用性を両立する新しい基準作りが今後の鍵です。
続きを読む
報道で注目された113本の論文と自動生成エージェントの課題を整理し、出典の明示と検証文化の強化、読者のリテラシー向上が信頼回復への実践的な道筋であることをやさしく解説します
続きを読む
物理学者スティーブ・フス氏がGPT-5由来の核心アイデアを軸に論文を発表し、AIを研究の出発点とする新潮流と透明性・再現性の重要性を示唆しています。
続きを読む

OpenAIの開発者Roonが、GPT-4oの応答が完全に再現できない理由を解説します。確率的サンプリングやバージョン差、コンテキストの違いが影響し、開発・運用での注意点と実務的な対策を具体例とともに整理しました。
続きを読む